BeautifulSoup, find와 select 를 사용한 웹 크롤링
파이썬을 배우고 몇 번 웹 스크레핑 (웹 크롤링)을 해보니 웹 스크레핑의 기본 프로세스는 대개 정해진 패턴이 있다는 것을 알게 되었습니다.
따지고 보면 웹 스크레핑이라는 것은 웹페이지에서 자신이 원하는 데이터를 긁어오는 것이므로 비교적 정형화된 작업입니다. 정형화된 작업은 정형화된 프로세스가 있으므로 이것을 정리해서 머리에 넣어 두는 것이 중요합니다.

왜냐하면, 코딩이 본업이 아닌 (요새는 생활 코딩이라는 표현을 많이 쓰더군요) 아마추어 프로그래머는 Daily Job으로 이런 일을 하지는 않기 때문에 기본이 흔들리면 이 일을 할 때마다 다시 명령어부터 찾아보아야 하는 불편이 따르고 시간을 소비해야 하기 때문입니다. 이런 일이 반복되면 이 일에 흥미를 잃어버릴 수도 있겠지요.
그래서 오늘은 일부러 시간을 내어서 웹 스크레핑 코딩의 기본 프로세스를 한번 정리해 보았습니다.
웹스크레핑 코딩의 기본 프로세스
1. 대상 웹페이지를 파싱 (Parsing by BeautifulSoup)
2. 파싱(Parsing)된 데이터중에서 스크레핑하고자 하는 "전체 데이터"를 선택함,
: 이때 find_all 또는 select 명령어를 사용하며 얻어지는 데이터는 리스트 형태임
: 이 리스트는 대부분 "대(大) 리스트"안에 "소(小) 리스트"들이 들어 있는 구조임.
3. 이 리스트형 데이터 안에서 직접 구하고자 하는 "단위 데이터"를 선택함.
: 이때 find 또는 select_one 명령어를 사용하며
: for 순환문을 이용하여 "2"에서 만들어진 "대(大) 리스트"안의 "소(小) 리스트"를 대상으로 "단위 데이터"를 스크레핑
: 대(大)리스트 = [ [소(小) 리스트 = 내부에 "단위 데이터"], [소(小)리스트], [소(小) 리스트],,,,,,]
4. 이렇게 얻어진 "단위 데이터"를 출력함.
: 출력은 단순하게 print문을 활용하거나 혹은 csv형태의 파일로 만들어서 출력해줌.
대상 웹페이지를 파싱 (by BeautifulSoup) : 위의 1단계
BeautifulSoup은 복잡한 구조로 되어 있는 웹페이지를 스크래핑 (혹은 크롤링이라고도 표현)이 용이하도록 단순한 구조의 데이터로 만들어 주는 파이썬의 라이브러리이고 이것을 활용하여 웹페이지를 데이터로 만드는 과정을 파싱(Parsing)이라고 합니다.
이 파싱은 대단히 복잡한 과정이겠지만 저희들이 고민할 필요는 없겠지요.
왜냐하면 파이썬 프로그램 안에서 이 라이브러리가 알아서 다 처리를 해주기 때문입니다.
프로그래머 입장에서는 필요한 기본 라이브러리들을 인스톨해주고, 코딩의 상단에 정형화된 형태로 기입을 해 주면 됩니다. (남들이 만들어 둔 코딩의 앞부분을 그대로 복사해서 사용하면 됨)
데이터 선택 과정 : 위의 2, 3단계
초보자 입장에서 현실적으로 어려움에 부딪히는 곳은 바로 이 단계입니다.
HTML 문서가 구조적인 형태로 되어 있으므로 원하는 웹페이지에서 스크래핑할 부분만 정확히 선택할 줄 알면 되는데 이게 경험도 많이 필요한 일인 것 같습니다.
특히 저처럼 코딩이 본업이 아니고 스크래핑할 일이 가끔 있는 경우에 처음에는 대충 이해했는 것 같았는데 한 두 달 지나서 생각하면 다시 헷갈리는 부분입니다.

그래서 데이터를 선택하기 위해서 사용하는 명령어인 find와 select에 대해서는 나만의 기준을 정리를 해 두어어야 합니다. 제가 정리한 것은 아래와 같습니다.
-기본적으로 find와 select 명령 중에서 어떤 것을 사용하더라도 같은 결과를 얻을 수 있다.
-2번의 "전체 데이터"를 얻기 위해서는 "find_all"을 사용하거나 "select"를 사용해야 한다.
-3번의 "단위 데이터"를 얻기 위해서는 "find"를 사용하거나 "select_one"을 사용한다.
-find와 select 모두 사용법이 매우 다양하므로 어느 한쪽을 어느 정도 숙지해 두는 것이 좋음.
-제 경우에는 처음에는 find 쪽을 많이 사용했는데, 지금은 select가 좀 더 편한 것을 알고 select를 많이 쓰게 됨.
-그 이유는 크롬 개발자 도구에서 "Copy selector"기능이 있어서 선택자를 쉽게 가져올 수 있기 때문.
그리고,
"find_all' 혹은 'select"로 얻어진 전체 데이터중에서 "find' or "select_one"으로 단위 데이터를 빼내기 위해서는 For 순환문을 사용합니다.
♣ 최근에 "은퇴 준비"라는 주제로 유튜브 채널을 개설했습니다.
경험을 바탕으로 한 "은퇴 준비" 콘텐츠와 이야기를 다루려고 합니다. 많은 응원 부탁드려요...😊😃😉
출력 부분 : 위의 4단계
출력 부분도 첫 단계인 파싱처럼 비교적 단순합니다.
Print문을 사용할 경우는 그냥 하면 되고, csv 포맷의 문서로 출력하려면 csv 라이브러리를 코딩 상단에 import 시켜 주고 간단한 명령어만 몇 줄 추가하면 됩니다.
예제로 설명해 봅니다.
위의 전체 프로세스 가운데서 2번째/3번째 단계인 데이터 선택 부분에 대해서 한 가지 사례를 가지고 설명을 해 보겠습니다.
● 스크레핑 대상 : 네이버 쇼핑의 휴대폰용 보조배터리의 Best 100 페이지
-URL : search.shopping.naver.com/best100v2/detail.nhn?catId=50004603
-가져올 데이터 : 1위 ~100위 제품 각각의 "제품명", "링크", "가격", "상품평 숫자" 데이터
● 전체 데이터와 단위 데이터
전체 데이터(大 리스트)는 아래 표시된 영역 (빨간색 사각형)의 단위 데이터 (小 리스트) 100개로 구성된 것입니다.
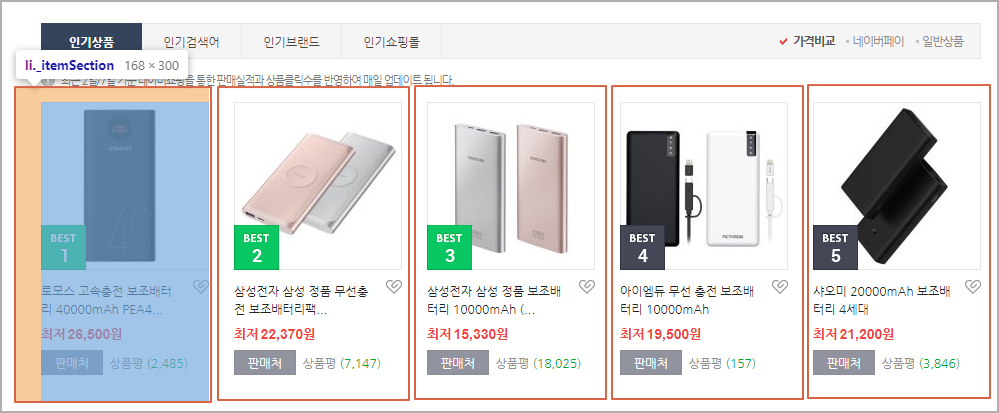
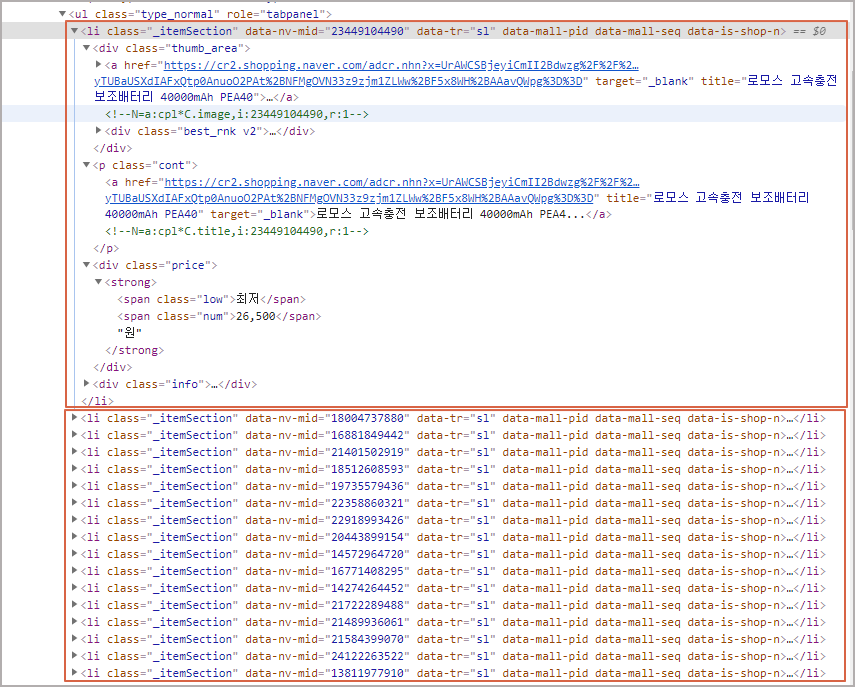
이 빨간색 사각형 부분은 크롬 관리자 도구 (F12)로 Element를 확인해 보면 class명이 "_itemSection"인 <li> 태그들인 것을 알 수 있습니다.
이 <li> 태그를 열어 보면 그 아래에는 <div>, <p>, <div>, <div>등의 다양한 태그들이 내재되어 있고 이 가운데에 우리가 가져오고 싶은 "품명", "링크", "가격", "상품평 숫자"등이 들어 있습니다.
그러면,
전체 데이터(大 리스트)를 확보하기 위하여 "find_all"명령어를 사용하거나 "select"를 사용해 봅니다.
● find_all을 사용한 경우
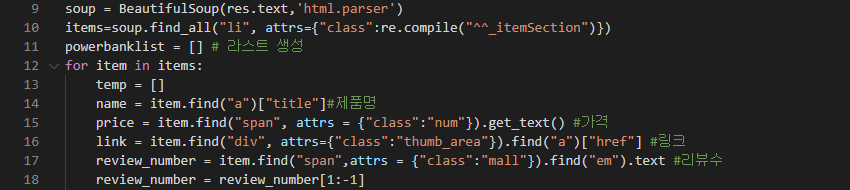
위에서 변수 items이 전체 데이터입니다.
items=soup.find_all("li, attrs={"class":re.compile(^_itemSection")})
위의 코드는 find_all 명령을 사용하여 class이름에 "_itemsSection"이 들어가는 모든 <li> 태그 (100개 되겠죠)를 긁어서 리스트 형태로 이 변수에 넣으라고 한 것입니다.
이렇게 전체 데이터 (리스트 형태의 데이터)를 확보한 다음에,
For 순환문을 사용하여 단위 리스트를 한 개씩 열어서,,,, "품명", "링크", "가격", "상품평 숫자"를 찾아서 각각을 name, price, link, review_number라는 변수에 넣습니다.
예를 들어서 리뷰수인 "review_number"에는 위에서 만들어진 단위 리스트 중에서 class명이 mall인 <span> 태그를 찾고, 그 아래 <em> 태그를 찾은 다음에 이 중에서 문자 (. text)만 가져와서 넣으라는 형태가 됩니다.
그 코딩이 아래와 같겠네요.
review_number = item.find("span", attrs = {"class":"mall"}),find("em").text
● select를 사용하여 코딩을 한 경우
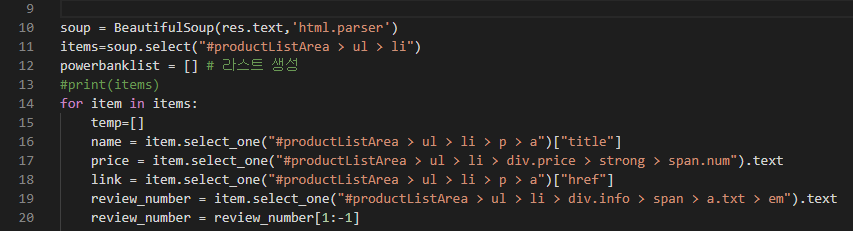
select 명령어를 사용해도 동일한 결과값을 얻게 됩니다.
그런데 좀 더 구조화되어 있어서 보기에는 더 헷갈려 보일 수가 있습니다.
하지만 이 경우에는 크롬 관리자 도구가 제공하는 기능을 사용할 수 있기 때문에 실수할 염려가 없고 좀 더 편합니다.
역시 items이 전체 데이터가 들어가는 변수입니다.
items = soup.select("#productListArea > ul > li")
위 코드에서 "#productListArea > ul > li" 부분이 Sector인데, 이 부분을 직접 입력하지 않고 아래와 같이 크롬 관리자 도구에서 <li> 태그 영역에 선택한 다음에 마우스 오른쪽 버턴을 눌러서 "Copy selector"를 선택하면 됩니다.
그러면, selector값으로 "#productListArea > ul > li:nth-child(1)"이 복사됩니다. 여기서 nth-child(1) 부분은 첫 번째 Li 값을 가리키므로 전체 데이터를 얻기 위해서 이 부분만 삭제해서 코딩에 붙여 넣기를 해주면 됩니다.
한결 간단합니다.
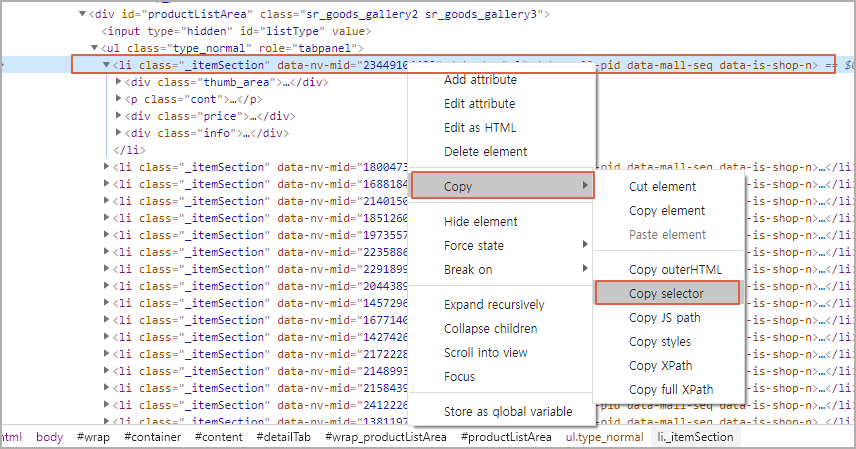
이렇게 해서 개별 <li> 태그 값이 들어있는 "단위 데이터" 100개가 포함된 "전체 데이터"가 리스트 형태로 items 변수에 할당이 됩니다.
이렇게 전체 데이터 (리스트 형태의 데이터)를 확보한 다음에,
For문을 사용하여 단위 리스트를 한 개씩 열어서,,,, name, price, link, review_number라는 변수에 넣습니다.
예를 들어서 리뷰수인 "review_number"의 경우에도 위에서 같은 방법으로 Copy selector를 가져오면 됩니다.
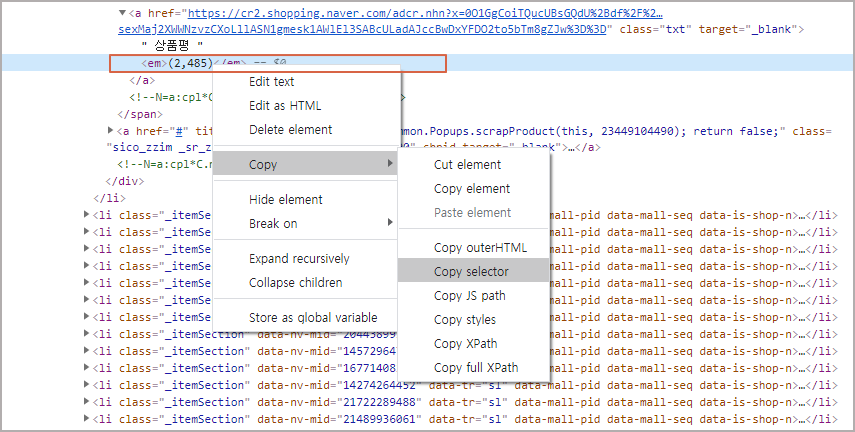
이렇게 얻어진 값이" "#productListArea > ul > li > div.info > span > a.txt > em"이고 여기서 텍스트 값(. text) 추출하면 됩니다.
이상으로 어떤 웹페이지를 스크렙핑(크롤링) 할 때 가장 큰 어려움을 겪는 데이터 선택 방법에 대해서 한번 정리를 해 보았습니다.
아래 코드는 find와 select의 2가지 방법을 사용한 코드로 얻어진 결과를 csv 파일로 저장하는 것입니다.
어느 쪽이나 동일한 결과를 얻을 수 있습니다.
● find_all을 사용한 경우
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import requests
import re
from bs4 import BeautifulSoup
import csv
url = "https://search.shopping.naver.com/best100v2/detail.nhn?catId=50004603"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text,'html.parser')
items=soup.find_all("li", attrs={"class":re.compile("^^_itemSection")})
powerbanklist = [] # 라스트 생성
for item in items:
temp = []
name = item.find("a")["title"]#제품명
price = item.find("span", attrs = {"class":"num"}).get_text() #가격
link = item.find("div", attrs={"class":"thumb_area"}).find("a")["href"] #링크
review_number = item.find("span",attrs = {"class":"mall"}).find("em").text #리뷰수
review_number = review_number[1:-1]
temp.append(name)
temp.append(link)
temp.append(price)
temp.append(review_number)
powerbanklist.append(temp)
# print(notebooklist[0])
with open('powerbanklist.csv',"w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f)
writer.writerow(['품명','링크','가격','리뷰수'])
writer.writerows(powerbanklist)
f.close
|
cs |
● select를 사용하여 코딩을 한 경우
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import requests
import re
from bs4 import BeautifulSoup
import csv
url = "https://search.shopping.naver.com/best100v2/detail.nhn?catId=50004603"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text,'html.parser')
items=soup.select("#productListArea > ul > li")
powerbanklist = [] # 라스트 생성
#print(items)
for item in items:
temp=[]
name = item.select_one("#productListArea > ul > li > p > a")["title"]
price = item.select_one("#productListArea > ul > li > div.price > strong > span.num").text
link = item.select_one("#productListArea > ul > li > p > a")["href"]
review_number = item.select_one("#productListArea > ul > li > div.info > span > a.txt > em").text
review_number = review_number[1:-1]
# print (review_number)
temp.append(name)
temp.append(link)
temp.append(price)
temp.append(review_number)
powerbanklist.append(temp)
with open('powerbanklist_select.csv',"w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f)
writer.writerow(['품명','링크','가격','리뷰수'])
writer.writerows(powerbanklist)
f.close
|
cs감가 |
아무것도 모르는 상태에서 파이썬 코딩을 독학으로 시작해서 이 정도까지 왔다는 것이 제 스스로가 대견스럽다는 생각이 드네요. 부족한 정리이지만 처음 시작하시는 분들께 작은 도움이 되었으면 좋겠습니다.
감사합니다.